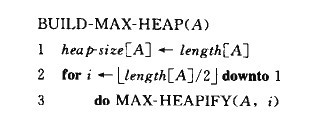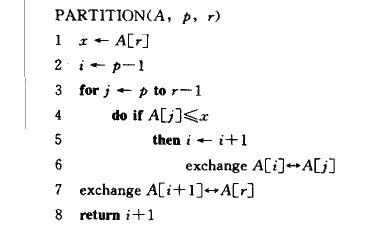算法基础(二)一
时间:2016-12-14作者:华清远见
堆排序 (二叉)堆数据结构是一种数组对象,它可以被视为一颗完全二叉树。树中每个节点与数组中存放该结点值的那个元素对应。 二叉堆有两种,大堆和小堆。 大堆的特性是:除了根节点,每个节点都不会大于其父节点。也就是说,每个节点的子节点的值都不会超过这个节点的值。这样,大的元素放在根节点处 小堆的特征正好相反,除了根节点外,每个节点都不会小于其父节点,也就是说小的元素放在根节点出。 在排序算法中,我们通常是使用大堆,小堆通常在构造优先队列时使用。 堆可以被看做一棵树,堆的高度为树根的高度。 为了创建一个大堆,我们使用堆排序的子程序max_heapify,其输入为一个数组a和下标i。这个子程序的目的是使以i为根的子树成为大堆。 length(A)是数组A中元素个数,heap-size(A)是存放A中的堆的元素个数。也就是说,虽然A中可能有元素,但是在heap-size(A)之外的元素都不属于堆。heap-size(A)<= length(A)。LEFT(i) 表示节点i的左孩子的标号,RIGHT(i)表示i节点右孩子的标号。
c语言实现如下: //heap_size 为一个整型全局变量,保存堆的大小。 建堆: 我们可以自底向上将一个数组构建为一个大堆。使用完全二叉树的性质,子数组a[(n/2 +1)......n] 中的元素都是树中的叶子节点,因此每个都可以看做是只有一个元素的堆。build_max_heap是对树中每个其他节点都调用一次max_heapify
建堆的过程,时间复杂度为O(n)。当然,我们可以利用小堆的概念,将这个建堆过程修改为创建一个小堆。 c语言实现如下: void build_max_heap(int *a,int size_a){ 堆排序算法: 在排序开始前,我们先用build_max_heap,将数组a构造成一个大堆。此时,数组大元素就在树根,我们可以把它和后一个元素互换位置。互换后,这个大元素就可以从堆中移除,然后调用max_heapify,使新生成的二叉树修正为大堆。这样,在堆中第二大的元素又会位于二叉树的树根。不断重复,直到堆中的元素降到2。 伪代码如下:
c语言实现如下: void heap_sort(int *a,int size_a){ 堆排序算法时间代价为O(n lg n)。其中调用build_max_heap的时间为O(n),n-1次heap_max_heapify调用,每次调用时间代价是O(lgn)。 快速排序 快速排序也是一种分治模式。 分解:数组a[p...r] 被分为两个子数组a[p...q - 1 ] 和 a[ q + 1 ... r] 使得a[p...q-1]中的每个元素都小于等于a[q],而且,小于等于a[q + 1 ... r ]中的元素 。 解决:通过递归调用快速排序,对子数组a[p ... q - 1] 和 a[q +1 ... r]排序。 合并:因为两个子数组是就地排序,将他们合并不需要操作。 下面的过程实现了快速排序:
c语言代码: void quick_sort(int *a,int p,int r){ 为了排序一个完整数组a,初调用的是quicksort(a,0,length(a))。 下面是partition过程,它对子数组a[p...r]进行就地排序:
c代码实现: int partition(int *a,int p,int r){ 快速排序的性能: 快速排序的运行时间与划分是否对称有关,而后者又与选择了那个元素来进行划分有关。如果划分是对称的,那么从算法的渐进意义上来讲,就与合并算法一样快,时间复杂度为O(n lg n) 。而如果划分不是对称的,那么算法渐进上就和插入算法一样慢,时间复杂度为O(n2)。 以上介绍的排序算法,都是比较排序算法。我们可以证明对含有n个元素的一个输入序列,任何比较排序算法在坏的情况下都要用到O(n lg n)次来进行排序。所以,合并排序和堆排序是渐进优的。 接下来我们来看看三种以线性时间运行的算法:计数排序、基数排序和桶排序。这些算法都用非比较的一些操作来确定排序顺序。 计数排序 计数排序假设n个输入元素中的每个都是介于0到k之间的整数,此处k为某个整数。当k = O(n)时,计数排序的运行时间是O(n)。 计数排序的基本思想就是对每一个输入元素x,确定出小于x的元素个数。有了这一信息,就可以把x直接放到它的终输出的位置上。 在计数排序算法的代码中,我们假定输入是个数组a[1...n],length[a] = n 。另外还需要两个数组:存放排序的结果放在B[1...n],以及提供临时存储区c[0...k]。
c语言实现: /* c[i]中包含了关于大小为i的元素的个数信息。例如,当比5小的元素个数为2两个时,5这个元素应该处于的位置为3。所以,我们才能迅速定位正确的排序位置。计数排序的时间复杂度是O(n),其优于我们常用的比较排序。计数排序中根本不出现比较,而是用了输入元素的实际值来确定它在数组中的位置。它需要知道存储在数组中元素的大值。并且,它需要一个临时数组来存放值域中所有的数值。速度的提升,需要付出空间上的代价。 计数排序的一个重要特性是它是稳定的:具有相同值的元素在输出数组中的相对次序与它们在输入数组中的次序相同。
发表评论
|